Scrape paginated tables in Python with beautifulsoup
Background
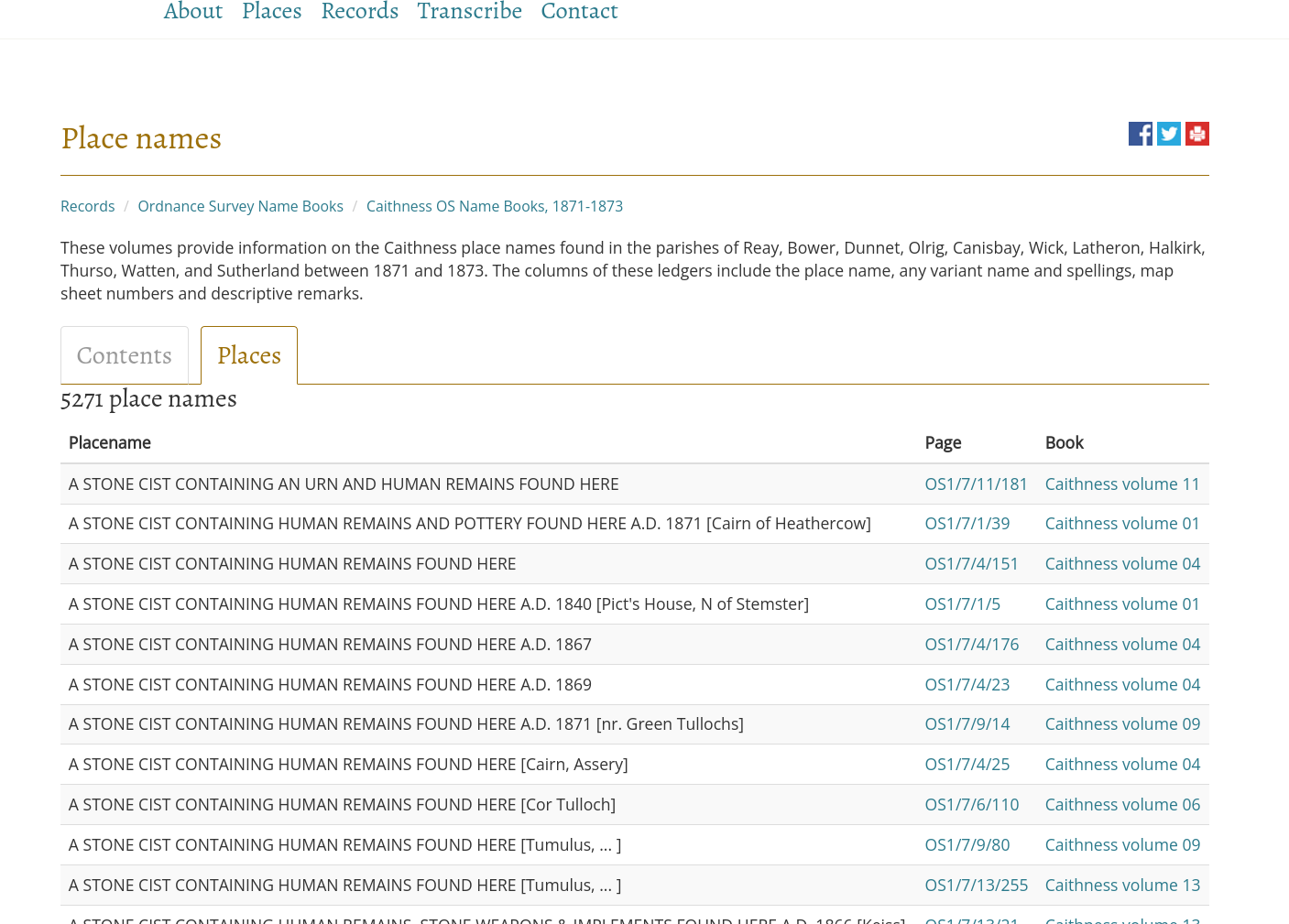
Say you want to extract a large table from multiple web pages without having to manually copy and paste. Ideally you would access the data from a website via an API. But some websites are just built for human readability and don’t provide this. However the salient information can be parsed out of web page elements in target pages in many cases. This is called scraping. Python provides easy methods to automatically retrieve and parse such data. This can be done with Beautiful Soup, a Python libary for pulling data out of HTML and XML files. For example, you might want to extract the tables inside a page. If they are paginated it represents another challenge. This post shows such an example. Note that some websites won’t like you scraping their pages in some cases and you should be careful about making many requests in a short time from a website.
Imports
You can install BeautifulSoup and requests with pip:
pip3 install pandas beautifulsoup4 requests
import pandas as pd
from bs4 import BeautifulSoup
import requests
Scraping
In this example we have a page with one table of placename listings which are paginated. Luckily the address indicates which page is shown. Thus an url for each page can be generated and parsed, then the data put together in to one table. Here we use pandas to store the table in a dataframe. soup.find("table") is enough to find the single table element. In other cases you may have to indicate the id of the element. So this is a specific solution for that page structure and you always need to tailor the code to the particular site. In the final part we iterate over the page numbers, so multiple requests are being made. Not the fastest method but it works.
def get_page(n):
"""parse a html table from a page"""
url = 'https://scotlandsplaces.gov.uk/digital-volumes/ordnance-survey-name-books/caithness-os-name-books-1871-1873?page=%s&display=placenames' %n
req = requests.get(url)
soup = BeautifulSoup(req.content, 'html.parser')
#get the table elements
rows = soup.find("table").find("tbody").find_all("tr")
result=[]
#iterate over rows and extract text data
for row in rows:
cells = row.find_all("td")
rn = [d.get_text() for d in cells]
#print (rn)
result.append(rn)
#return a dataframe
return pd.DataFrame(result,columns=['placename','page','book'])
res=[]
for page in range(0,264):
df = get_page(page)
res.append(df)
res=pd.concat(res)
The result is a dataframe of the form
placename page book
0 A STONE CIST CONTAINING AN URN AND HUMAN REMAI... OS1/7/11/181 Caithness volume 11
1 A STONE CIST CONTAINING HUMAN REMAINS AND POTT... OS1/7/1/39 Caithness volume 01
2 A STONE CIST CONTAINING HUMAN REMAINS FOUND HERE OS1/7/4/151 Caithness volume 04
3 A STONE CIST CONTAINING HUMAN REMAINS FOUND HE... OS1/7/1/5 Caithness volume 01
4 A STONE CIST CONTAINING HUMAN REMAINS FOUND HE... OS1/7/4/176 Caithness volume 04