Deaths in Ireland from RIP.ie - another look
Background
See updated analysis here and here.
In a previous post I looked at Ireland estimates of daily deaths from RIP.ie over 2019 and 2020. This data was obtained by manual copying of the results tables from the web page. This is tedious and misses other information in the actual death notice page that might be useful such as address or even place of death. Note: The plots here may have been subsequently updated after the original post to reflect newer data.
Better method
Another method is to automatically retrieve pages by their numerical id and parse the salient information out of the key web HTML elements. This can be readily done with Beautiful soup, a Python libary for pulling data out of HTML and XML files. This works because each entry in the site has a unique ID that is present in the URL. Some persons are entered multiple times but this can be more or less accounted for later by detecting duplicates in name and address/notice. The code to do this is given below in the drop down. It will return results of the form:
('Margaret Kelly',
datetime.datetime(2019, 6, 5, 0, 0),
'Cork',
'Avenue Grove, Ballymodan Place, Bandon, Cork',
"Kelly (Avenue Grove, Ballymodan Place, Bandon and late of Currivreeda West) on June 5th 2019. Margaret, beloved daughter of the late Timothy and Ellen. Sadly missed by her loving sisters Ann and Eileen, brothers Teddy and John, Margaret's Partner William, brothers-in-law, sisters-in-law, nieces, nephews, relatives and good friend Malcolm.;;Rosary on Friday evening at 7pm in St. Patrick's Church, Bandon. Requiem Mass on Saturday at 12 noon, funeral afterwards to the adjoining cemetery.;;May Margaret Rest in Peace")
We can then make the same plots as before but with more data. The plotting code is more or less the same as the previous post and can be found in the Jupyter notebook here.
import time
import pandas as pd
from bs4 import BeautifulSoup
import requests
import datefinder
def get_dn_page(n):
"""Get death notice text from page matching the id number"""
url = 'https://rip.ie/showdn.php?dn=%s' %n
req = requests.get(url)
soup = BeautifulSoup(req.content, 'html.parser')
title = soup.title.text.strip()
name=''
for s in ['Death Notice of ','The death has occurred of ']:
if title.startswith(s):
name = title.split(s)[1]
elem = soup.find_all("div", id="dn_photo_and_text")
if len(elem) == 0:
return name, '', '', '', ''
rows = elem[0].find_all('p')
if len(rows) == 0:
rows = elem[0].find_all('td')
text = ';'.join([r.text.strip() for r in rows]).replace('\n','')
#address
addrelem = soup.find("span", class_='small_addr')
if addrelem != None:
address = addrelem.text.strip()
else:
address = ''
#county
ctyelem = soup.find("li", class_='fd_county')
if ctyelem != None:
county = ctyelem.text.strip()
else:
county = ''
#date
dateelem = soup.find("div", class_='ddeath')
if dateelem == None:
dateelem = soup.find("div", class_='dpubl')
s = dateelem.text.strip()
try:
date = list(datefinder.find_dates(s))[0]
except:
date = ''
print (n, date, name, address, county)
return name, date, county, address, text
#read current table in so we skip those already done
df = pd.read_csv('rip_dn_scrape.csv',index_col=0)
ids = list(df.index)
results={}
for n in range(390000,461389):
if n in ids:
continue
name,date,cty,addr,txt = get_dn_page(n)
if text != '':
results[n] = [name,date,cty,addr,txt]
time.sleep(0.05)
res = pd.DataFrame.from_dict(results,orient='index',columns=['name','date','county','address','notice'])
res = pd.concat([df,res])
res.to_csv('rip_dn_scrape.csv')
#remove duplicates
x=res.replace('',None).dropna(how='any')
x['date'] = pd.to_datetime(x['date']).apply(lambda x: x.strftime('%d/%m/%Y'))
x=x.drop_duplicates(['name','notice'])
x=x.drop_duplicates(['name','address'])
print (len(res),len(x))
x.to_csv('rip_dn_scrape_processed.csv')
Totals
Note that these plots are the raw values and not age adjusted. Normally such data is adjusted to reflect the age profile of the population for each year. This is a standardisation required for year to year comparisons.
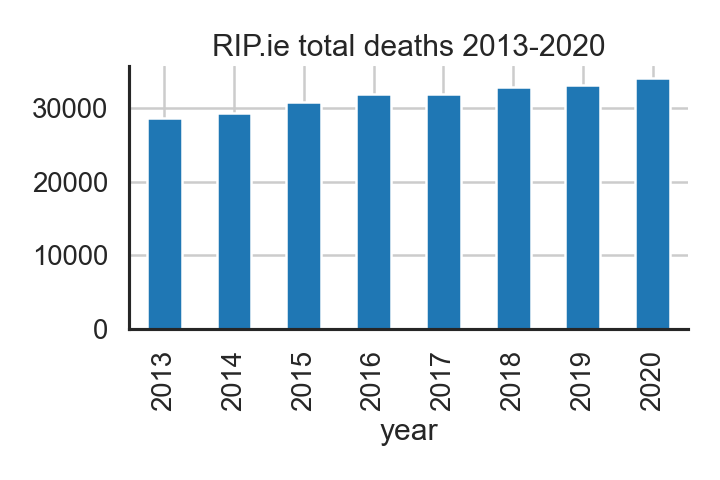
Yearly totals compared.
By month
Deaths by month per year are shown here.
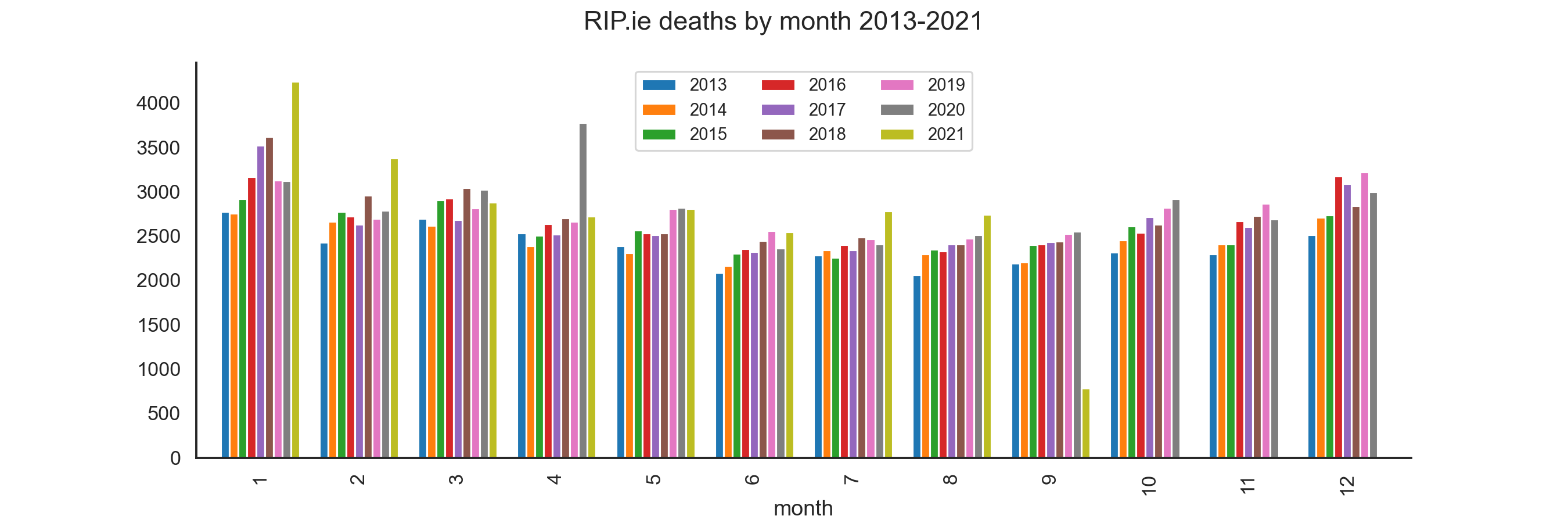
Monthly totals compared.
Years compared
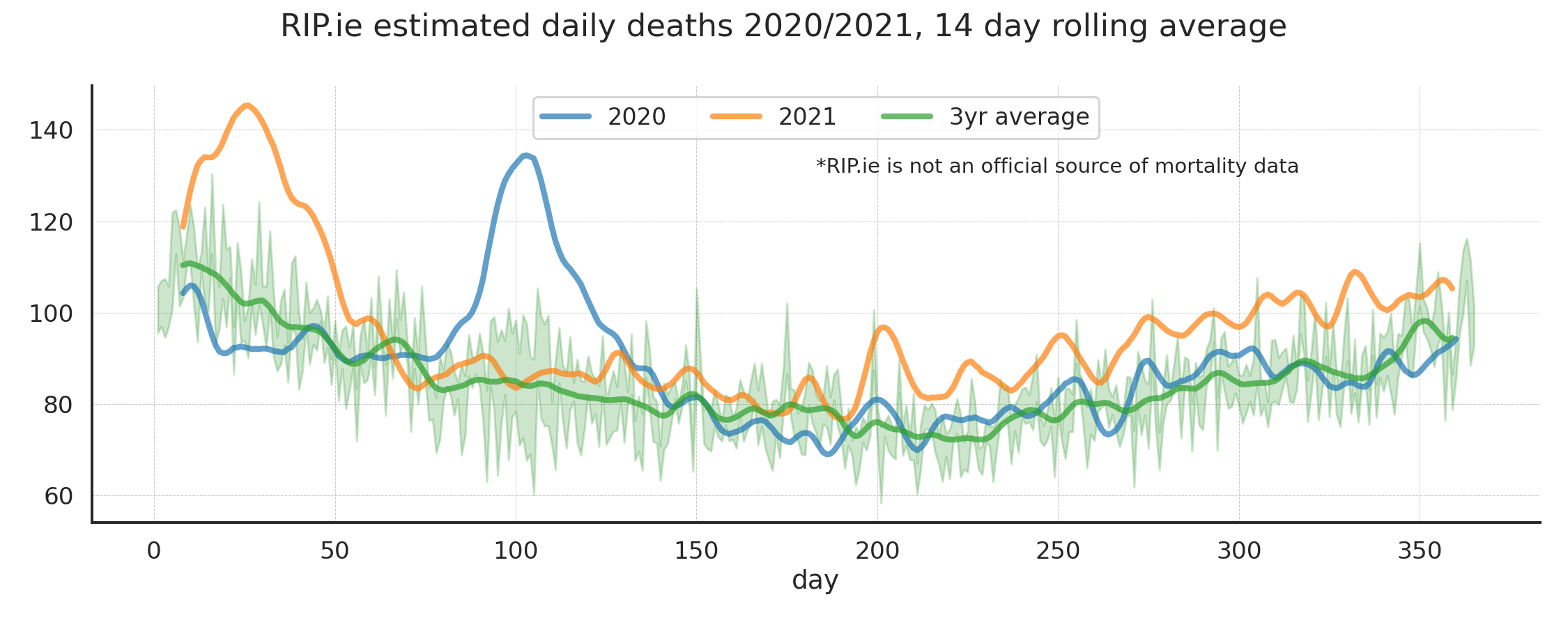
Averages for each year plotted over the same time scale.
Check against registered deaths
As a check that our RIP data are accurate we can compare the RIP deaths to the GRO monthly data. We can see that the RIP.ie deaths are often slightly higher than GRO. Except in 2013 when they seem a bit lower than expected. I do not know the reason for these differences. Duplicates in the RIP data may still be present which might account for some of this. Also the large differences in 2020 are probably because the GRO data for that year is incomplete.
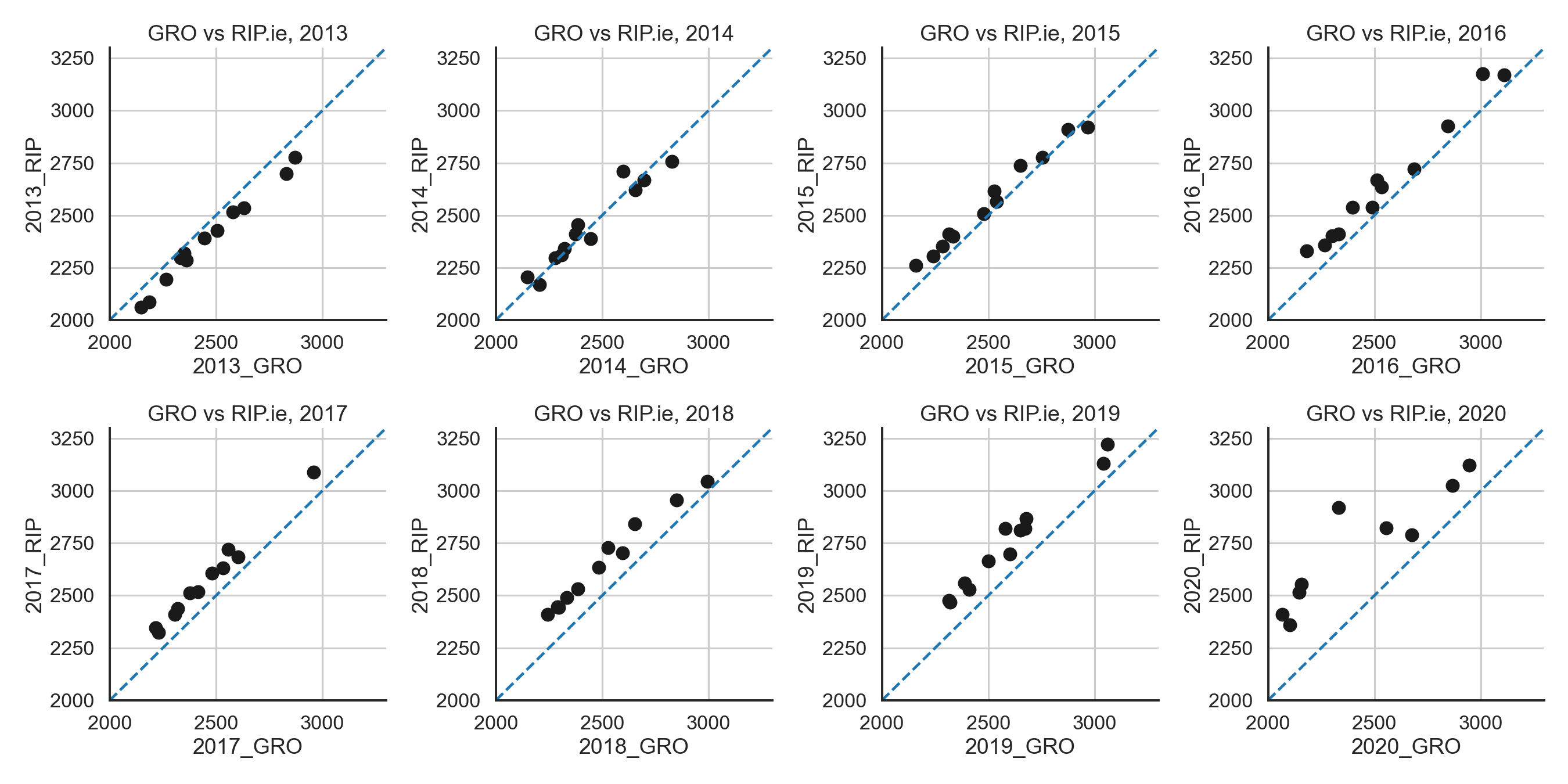
GRO vs RIP deaths.